
ScholarGPT:学术科技文档GPT
大数据时代,与科技相关的各类文献和互联网信息呈爆炸性增长。从需求侧看,科研人员面临着信息处理能力不足和认知能力有限的问题;从供给侧看,尽管目前的模型工具虽然能够为科研创新提供较为准确的信息以及常规知识聚合服务,但是仍未能与科研创新活动形成深度嵌入,各种多样化的模型技术工具无法有效整合,面对复杂场景缺乏协同;传统模型存在对数据标注规模要求高、模型迁移困难、多模态信息融合差、应急落地慢等问题;如何为科学研究提供个性化、细粒度、场景化的知识?
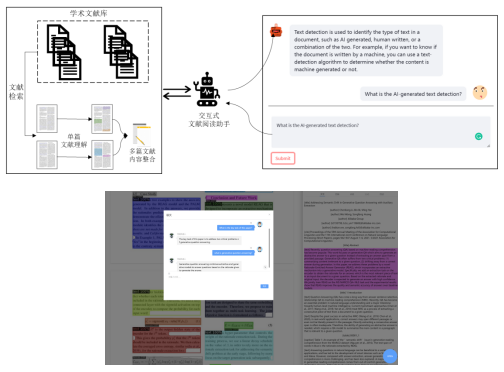
团队研发学术科技ScholarGPT大模型,以嵌入科研人员创新全过程中关键场景和任务的形式,实现对科研人员创新活动的赋能。底层架构上:ScholarGPT大模型采用GPT架构。为了使得模型具备学术知识理解能力,本团队基于WOS、SciHub、Arxiv、Pubmed、GitHub等多种数据在底座模型上进行训练调优,结合自指令学习、知识蒸馏、基于AI反馈的强化学习、价值对齐等技术,实现模型能力的构建,除了具备基本的文档信息处理能力,如信息抽取、自动摘要、问答、纠错、续写等,还能够支持多模态信息处理能力、鲁棒分析能力、多样化输出能力、场景适配的专业外部工具理解和调用能力,形成智能知识转化器推动科学知识的快速资源化利用、智能科研助理形成高效人智协作科研创新模式、智能服务平台推动多学科智能技术协同运用。
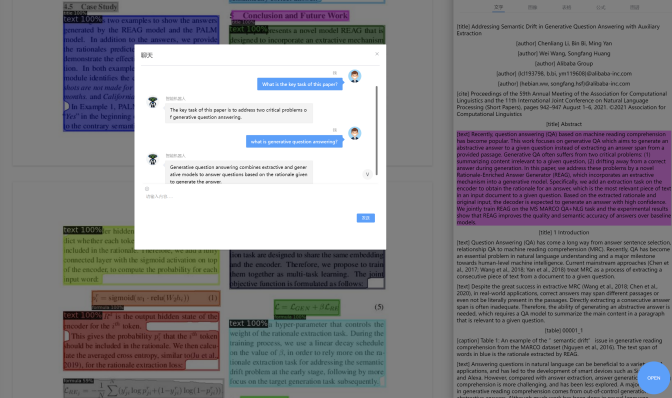
本团队构建了以ScholarGPT为底座的应用系统ScienceAI,为科研人员提供学术论文交互式阅读、数据自动处理、实验结果结构化分析和论文写作素材的生成与整合。同时结合不同学科、不同科研任务,设计场景化的prompt 库,为用户提供菜单式的科研辅助服务。
目前团队积累的轻量级模型英文语料规模超7TB,其中学术语料规模约1TB,中文语料规模超400GB web语料和100GB学术语料,已收集20万以上指令学习语料。大模型已实现1B和6B两个数量级的底座构建,轻量级模型完全自建、中量级模型指令微调和蒸馏实现,未来还将扩展实现大量级模型,并逐步从基于AI反馈的强化学习转换到基于人类反馈的强化学习。