
6
2015
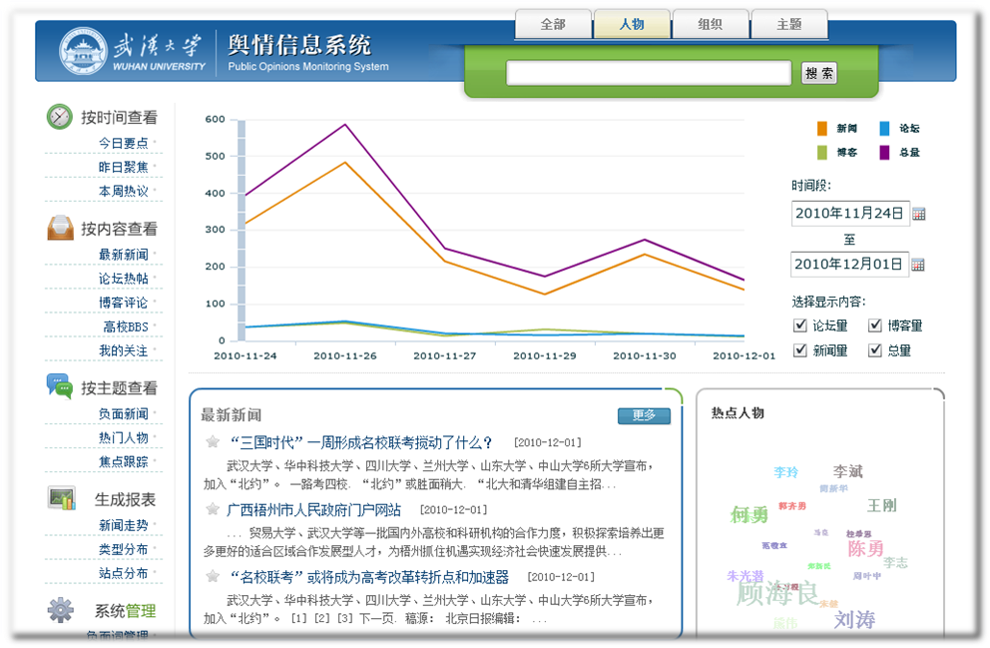
WHU-POMS舆情信息跟踪系统
WHU-POMS是针对武汉大学为例设计实现了一套完整的网络舆情监控系统,全面跟踪互联网上与该组织有关的新闻报道,及时识别新闻热点与敏感新闻。
武汉大学网络舆情监控系统中,信息源的采集主要是实时获取搜索引擎的检索结果和对指定站点的自动采集相结合的方式。首先以“武汉大学”、“武大”为关键字,调用Google、Bing、百度、搜狗、有道5个搜索引擎对这两个关键词的检索结果,获取最新的新闻页面;再对各个搜索引擎的返回结果去重整合,返回按时间倒序的新闻列表。
利用本系统的采集方式,每天能采集到几百到上千条与武汉大学有关的网页,系统运行10个月以来,总共采集到了近26万条数据,基本涵盖了网络上这段时间与武汉大学有关的新闻,能够满足全面监控武汉大学相关网络舆情的需要。
新闻过滤与预处理模块中,系统先利用正文提取工具获取网页的正文内容,再对新闻正文内容进行分句、分词处理。笔者采用了中科院分词包ICTCLAS 2010版作为分词、词性标注和实体标注工具,在前期采集到的24218篇新闻网页上统计关键词出现的文档频率,最后确定了文档频率在1%--10%的7642个关键词构建向量空间,同时生成这些关键词的DF表。将所有的新闻文档都表示成7642维的向量,每个维度上的权重采用优化的BM25方法计算,先统计文档中关键词的词频(TF),再根据关键词在新闻文档中的位置和词性加权,最后构建权值向量。
系统采用了两层聚类的方法发现热点事件,首先提取每天的新闻记录,按照网页获取的时间顺序,依次提交给在线增量聚类器,聚类器根据single-pass算法聚类形成每天的微类,微类表示当天的热点新闻。然后提取一周内每天聚合形成的微类,将这些微类再进行一次凝聚聚类,把微类聚合形成新的聚簇。这样便可得到一周内新闻报道的聚簇,统计每个聚簇内的网页数目,其中聚蔟内网页数量较多的一部分事件即为本周的热点事件。
系统利用分类的方法识别与武汉大学有关的敏感新闻,首先确立与武汉大学这个组织有关的敏感词汇,把每个词汇表示成一个描述文档,通过计算新闻文档与描述文档的相似性来识别是否为敏感新闻。识别出敏感新闻文档后,根据敏感词与武汉大学的位置和文本距离对新闻的敏感度评分,如果敏感词与武汉大学在同一句子中,相应敏感度值高;如果敏感词与武汉大学的距离很远,则相应的敏感度较低,最后对敏感度值大于设定阈值的新闻提出预警。
最后构建了一个基于J2EE的B/S模式舆情监控系统平台,通过浏览器可以查看所有舆情报告。
第二届技术创新与技术竞争情报国际会议大会报告PPT 点击下载
